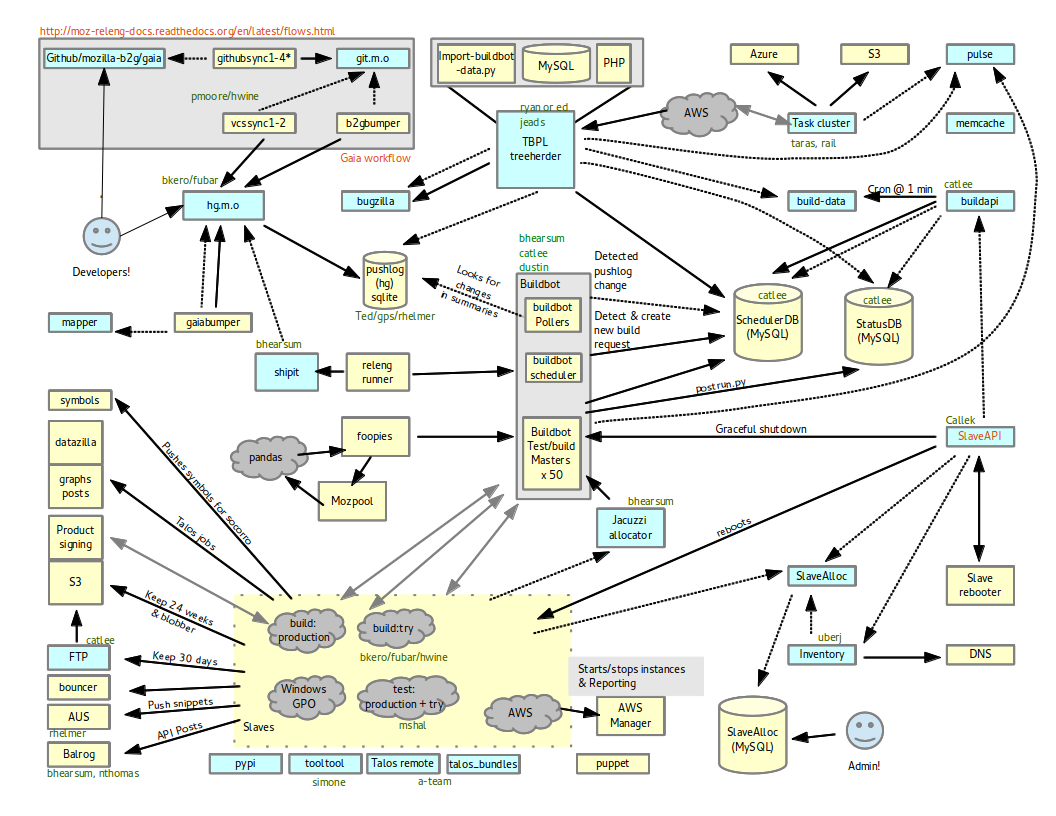
Back on May 7, Ben Hearsum gave a short talk about an important piece of technology supporting our transition to TaskCluster, the Buildbot Bridge. A recording is available.
I took some detailed notes to spread the word about how this work is enabling a great deal of important Q3 work like the Release Promotion project. Basically, the bridge allows us to separate out work that Buildbot currently runs in a somewhat monolithic way into TaskGraphs and Tasks that can be scheduled separately and independently. This decoupling is a powerful enabler for future work.
Of course, you might argue that we could perform this decoupling in Buildbot.
However, moving to TaskCluster means adopting a modern, distributed queue-based approach to managing incoming jobs. We will be freed of the performance tradeoffs and careful attention required when using relational databases for queue management (Buildbot uses MySQL for it’s queues, TaskCluster uses RabbitMQ and Azure). We also will be moving “decision tasks” in-tree, meaning that they will be closer to developer environments and likely easier to manage keeping developer and build system environments in sync.
Here are my notes:
Why have the bridge?
- Allows a graceful transition
- We’re in an annoying state where we can’t have dependencies between buildbot builds and taskcluster tasks. For example: we can’t move firefox linux builds into taskcluster without moving everything downstream of those also into taskcluster
- It’s not practical and sometimes just not possible to move everything at the same time. This let’s us reimplement buildbot schedulers as task graphs. Buildbot builds are tasks on the task graphs enabling us to change each task to be implemented by a Docker worker, a generic worker or anything we want or need at that point.
- One of the driving forces is the build promotion project – the funsize and anti-virus scanning and binary moving – this is going to be implemented in taskcluster tasks but the rest will be in Buildbot. We need to be able to bounce between the two.
What is the Buildbot Bridge (BBB)
BBB acts as a TC worker and provisioner and delegates all those things to BuildBot. As far as TC is concerned, BBB is doing all this work, not Buildbot itself. TC knows nothing about Buildbot.
There are three services:
- TC Listener: responds to things happening in TC
- BuildBot Listener: responds to BB events
- Reflector: takes care of things that can’t be done in response to events — it reclaims tasks periodically, for example. TC expects Tasks to reclaim tasks. If a Task stops reclaiming, TC considers that Task dead.
BBB has a small database that associates build requests with TC taskids and runids.
BBB is designed to be multihomed. It is currently deployed but not running on three Buildbot masters. We can lose an AWS region and the bridge will still function. It consumes from Pulse.
The system is dependent on Pulse, SchedulerDB and Self-serve (in addition to a Buildbot master and Taskcluster).
Taskcluster Listener
Reacts to events coming from TC Pulse exchanges.
Creates build requests in response to tasks becoming “pending”. When someone pushes to mozilla-central, BBB inserts BuildRequests into BB SchedulerDB. Pending jobs appear in BB. BBB cancels BuildRequests as well — can happen from timeouts, someone explicitly cancelling in TC.
Buildbot Listener
Responds to events coming from the BB Pulse exchanges.
Claims a Task when builds start. Attaches BuildBot Properties to Tasks as artifacts. Has a buildslave name, information/metadata. It resolves those Tasks.
Buildbot and TC don’t have a 1:1 mapping of BB statuses and TC resolution. Also needs to coordinate with Treeherder color. A short discussion happened about implementing these colors in an artifact rather than inferring them from return codes or statuses inherent to BB or TC.
Reflector
- Runs on a timer – every 60 seconds
- Reclaims tasks: need to do this every 30-60 minutes
- Cancels Tasks when a BuildRequest is cancelled on the BB side (have to troll through BB DB to detect this state if it is cancelled on the buildbot side)
Scenarios
- A successful build!
Task is created. Task in TC is pending, nothnig in BB. TCListener picks up the event and creates a BuildRequest (pending).
BB creates a Build. BBListener receives buildstarted event, claims the Task.
Reflector reclaims the Task while the Build is running.
Build completes successfully. BBListener receives log uploaded event (build finished), reports success in TaskCluster.
- Build fails initially, succeeds upon retry
(500 from hg – common reason to retry)
Same through Reflector.
BB fails, marked as RETRY BBListener receives log uploaded event, reports exception to Taskcluster and calls rerun Task.
BB has already started a new Build TCListener receives task-pending event, updates runid, does not create a new BuildRequest.
Build completes successfully Buildbot Listener receives log uploaded event, reports success to TaskCluster.
- Task exceeds deadline before Build starts
Task created TCListener receives task-pending event, creates BuildRequest Nothing happens. Task goes past deadline, TaskCluster cancels it. TCListener receives task-exception event, cancels BuildRequest through Self-serve
QUESTIONS:
- TC deadline, what is it? Queue: a task past a deadline is marked as timeout/deadline exceeded
On TH, if someone requests a rebuild twice what happens? * There is no retry/rerun, we duplicate the subgraph — where ever we retrigger, you get everything below it. You’d end up with duplicates Retries and rebuilds are separate. Rebuilds are triggered by humans, retries are internal to BB. TC doesn’t have a concept of retries.
-
How do we avoid duplicate reporting? TC will be considered source of truth in the future. Unsure about interim. Maybe TH can ignore duplicates since the builder names will be the same.
-
Replacing the scheduler what does that mean exactly?
- Mostly moving decision tasks in-tree — practical impact: YAML files get moved into the tree
- Remove all scheduling from BuildBot and Hg polling
Roll-out plan
- Connected to the Alder branch currently
- Replacing some of the Alder schedulers with TaskGraphs
- All the BB Alder schedulers are disabled, and was able to get a push to generate a TaskGraph!
Next steps might be release scheduling tasks, rather than merging into central. Someone else might be able to work on other CI tasks in parallel.